准备面试工作
本文最后更新于:7 个月前
项目技术栈记载
web应用开发
基于SSM框架的网上商城开发
技术栈
SSM框架
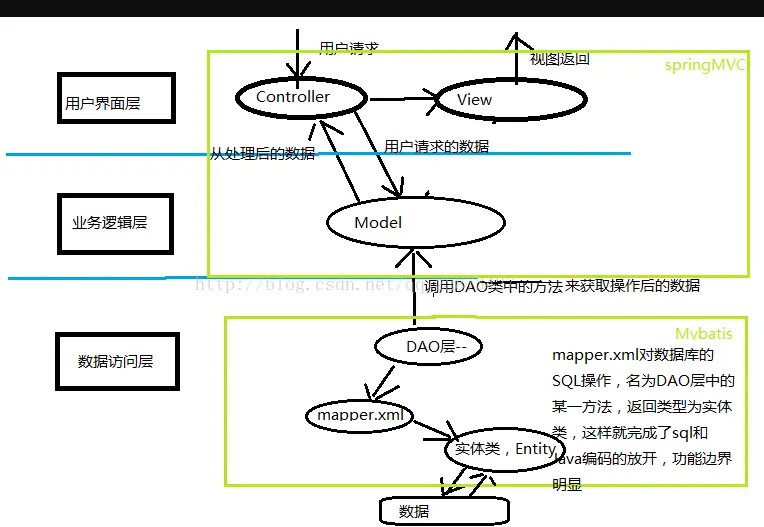
SSM框架是spring MVC ,spring和mybatis框架的整合,是标准的MVC模式,将整个系统划分为表现层,controller层,service层,DAO层四层
各部分的功能:
- 使用spring MVC负责请求的转发和视图管理
spring实现业务对象管理
mybatis作为数据对象的持久化引擎
基础原理
(概念?特点?作用?设计理念?)
1️⃣javabean
相当于将一个java类封装成了一个可重用组件,比如一个类student,这个bean里面包括了
student.number、student.score、student.name等属性以及对于这些属性值的修改设置等操作,全都封装在一个类中,并且可以在前端JSP页面调用获取数据,或是执行数据库访问操作等,使用这个对象举例:
比如我们在通过访问数据库获取到某个学生的姓名后,通过student.setName()的方法就可以把获取的数据保存在student的实例对象中,接着可以通过JSP页面的请求调用这一对象的数据,以student.getName()方法来获取;
- 一个javabean包含如下特点
- JavaBean可以调用的方法
xxx.getA()、xxx.setA() - JavaBean提供的可读写的属性
xxx.a - JavaBean向外部发送的或从外部接收的事件
- 全局使用,但内部细节封装,只需生成实例来调用,相当于给一个接口与外界联系
- JavaBean可以调用的方法
2️⃣spring
- Spring是一个轻量级的IOC和AOP容器框架。是为Java应用程序提供基础性服务的一套框架,目的是用于简化企业应用程序的开发,它使得开发者只需要关心业务需求。主要包括以下七个模块:
Spring Context:提供框架式的Bean访问方式,以及企业级功能(JNDI、定时任务等);
Spring Core:核心类库,所有功能都依赖于该类库,提供IOC和DI服务;
Spring AOP:AOP服务;
Spring Web:提供了基本的面向Web的综合特性,提供对常见框架如Struts2的支持,Spring能够管理这些框架,将Spring的资源注入给框架,也能在这些框架的前后插入拦截器;
Spring MVC:提供面向Web应用的Model-View-Controller,即MVC实现。
Spring DAO:对JDBC的抽象封装,简化了数据访问异常的处理,并能统一管理JDBC事务;
Spring ORM:对现有的ORM框架的支持;
3️⃣mybatis
- 支持普通 SQL查询,存储过程和高级映射的优秀持久层框架。MyBatis 消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。MyBatis 使用简单的 XML或注解用于配置和原始映射,将接口和 Java 的POJOs(Plain Ordinary Java Objects,普通的 Java对象)映射成数据库中的记录。简单说:实现对数据库的操作不必像单纯使用sql语句那样复杂,正如一个类提供的接口一样,我们可以通过编写映射关系来封装某一种数据的操作
4️⃣springMVC
- 一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把
Model,View,Controller分离,将web层进行职责解耦,把复杂的web应用分成逻辑清晰的几部分,简化开发,减少出错,方便组内开发人员之间的配合。
SMM 工作原理
工作流程:浏览器发送数据请求,即在web层执行相应的controller,通过controller调用相应的service并配合MyBatis的使用对数据库进行各种便捷的操作以获取请求的数据,然后逐步返回数据到浏览器中进行渲染
- 表现层(Web):即负责渲染页面以及前后端之间的数据传递
- 业务层(Service):按照业务要求去封装对数据层的操作(登录、注册账号这些都封装为接口)
- 数据访问层(DAO层)/持久层:负责直接对数据库操作以及提供给业务层调用的接口
spring管理持久层的mapper,mapper通过映射可以实现关于数据库MySQL的SQL语句操作(比如查询数据等),相当于对外提供了一个数据库操作的接口,并且比直接使用sql语句对数据操作来的更加安全和方便、无需知道内部细节
业务层的service接口可以调用mappert提供的接口,也就是说我们在service层间接的实现了对数据库的操作,按照我们的目的带入参数去调用这些接口,就可以获取到数据保存到类的实例中(bean对象),而service 层又通过封装一些方法函数作为接口给到controller层,比如在controller请求数据后回传。
- 数据层,实现对数据库的增删查改操作,为什么要用mybatis?
举例:展示mybatis的工作原理
- 若要实现一种自定义的数据操作,可以发现实际就是将某一个操作与sql语句进行了映射,这样对于调用该接口的操作者来说无需知道细节,有利于各层的独立开发;更多XML映射器的写法见mybatis – MyBatis 3 | XML 映射器
1 | |
1 | |
Android 应用开发
股票行情分析软件
技术栈/应用框架,工具
1️⃣总览
- java-Echarts 数据可视化插件,是echarts这一可视化库在java语言上的拓展实现
- okhttps3多线程网络请求
- jsoup网络爬取解析工具
- fastjson 通过解析json文件提取数据的工具
2️⃣详细原理
爬数据 Okhttp3
- 软件内获取到的数据由于都是来自网络,因此需要先确定爬取源数据的网站,找的是某个股票资讯网站;
- 解析网站的网页源码,使用okhttp3可以发送一个client(客户端如浏览器)的网络请求至目标网址,然后将请求返回的网页源码转成字符串数据,那么我只需要在找出数据在原网页代码中的位置,调用相应的方法就可以在这一大串的字符串中指定截取出数据并保存到定义好的java对象实例中以便后续调用;
为何要用异步请求?
- 同步请求是顺序处理网络请求,多个请求依次被响应,可想而知,如果排在前面的请求迟迟不被响应,将会浪费时间和内存,较少了程序运行效率
- 异步请求则不同,可以被并行处理,在服务器响应返回结果之前,程序可以进行其他的操作,这和计算机组成原理的DMA方式异曲同工,但DMA讲的是总线控制权的问题,当DMA准备工作做好时,CPU主动让出总线控制权进行DMA工作
优缺点
优点
okhttp3可以在网络请求的任意步骤中intercept 阻拦(拦截器)
在异步请求中,通过Callback来获得简单清晰的请求回调(onFailure、onResponse)
可实现同一IP地址和端口的请求重用一个socket能够大大降低网络连接时间提高效率,也降低了服务器的压力
支持多线程请求,这样可以提高程序运行效率,
缺点
- 由于请求回调是在子线程中执行的,因此不能(主线程就是UI线程,负责更新UI)及时刷新android 的UI,当然也有办法,主要是
runOnUiThread()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16final Handler mHandler = new Handler();
private Thread mUiThread;
// ...
public final void runOnUiThread(Runnable action) {
if (Thread.currentThread() != mUiThread) {
mHandler.post(action);
} else {
action.run();
}
// ...
}
//首先在主线程里通过无参的构造方法创建一个Handler,这个Handler是指向主线程的。Handler是负责放置消息的
//当执行runOnUiThread()时,当前线程不是主线程
//调用mHandler.post(action),将Runnable添加到主线程的消息队列中这样,Runnable的语句就是在主线程执行的了。- 由于请求回调是在子线程中执行的,因此不能(主线程就是UI线程,负责更新UI)及时刷新android 的UI,当然也有办法,主要是
解析数据
- okhttp3获取到网页HTML代码的字符串后,需要通过jsoup来解析,首先需要将html字符串内容转换成document类才能根据html标签等方式进行更方便的解析以获取数据集,主要以
doc.select("div[class='...']")这样的方式获取
UI设计与数据的渲染
- 将数据获取并解析后,保存到一开始就定义好的类的实例对象中,就可以在activity中调用了,剩下的工作就是将数据和UI界面的常用组件绑定在一起,运行打包好的软件就可以实时看到了
模糊搜索与全局搜索
- 用什么算法较好?
优化设计
- 股票信息全局的搜索
- 下拉刷新最新的新闻资讯(WebView)
- UI的美化
- 用户信息的存储
机器学习实战
垃圾分类
实现步骤
- 数据准备
- 网络配置
- 模型训练
- 模型验证
- 模型预测
- 将模型下载到本地,使用模型对目标进行预测,看能否正确预测(在本地写代码进行测试)
- 模型部署,开发应用
开发记录
问题与解决方案
华为云的垃圾分类数据集
ImageNet格式下的垃圾分类图片数据
网络结构与改进 ResNet - ResNet SSLD
VGG 重复3*3的小卷积结构增加网络深度,深度增加感受野增加,同时学习到更丰富的网络特征。
GoogLeNet通过不同尺度的卷积核堆叠增加网络宽度,学习不同尺度的信息。
ResNet使用残差结构使网络拥有恒等映射的能力,改善网络退化问题。
优化方案
- 比较选择合适优化器
- 迁移学习(需要深入理解)
- 需要对比:选择不同的优化器和学习率以及batch_size来进行训练,并形成对比(如何制作对比图表)
知识补充
网络模型
1️⃣LeNet 老模型了,具有学习意义
2️⃣ AlexNet
- LRN
- ReLu
- Dropout
3️⃣ VGGNet
- 非线性映射能力-因为参与影响的因素越多,关系是多维的而且不是直线的?
4️⃣
关于一些代码的原理分析
- HWC to CHW : 由于要采用GPU进行训练,将数据的形状转换有利于GPU的训练
- IMG *= 0.007843 :像素值归一化的操作,亦有 IMG/=255 ,但这个浮点数为何而来
- 使用CPU还是GPU进行训练
1 | |
遭遇问题
- 训练过程中要记录每一batch完之后的损失以及正确率等,但是在训练的过程中往往最后一次得到的参数并不是最佳的,由于算法的缺陷导致参数的不稳定,那么我们怎么能够在训练完之后,选出这之中训练效果最好的一次呢?也就是说我们需要保存最佳的一次参数?
如何做--K折交叉验证
- [x] 保存训练过程中的最佳模型(实际是参数的集合)
- [x] 将训练过程的指标可视化
Django+小程序开发
项目思路
客户端(小程序)
1️⃣界面的设计
小程序的界面依据功能需求分析,主要分为首页、用户信息页(两个足够);分类百科(用户直接浏览各种垃圾所属分类的信息)
首页
元素设计:
[x] 触发查看用户信息页面的图标
[x] 文本搜索按钮进入,方案
1️⃣
弹出一个小窗口可以输入然后返回结果2️⃣直接跳转到一个比较缺少内容的简单页面直接输入文本进行搜索,然后再弹窗输出结果;并还能够在该页面增加一个额外的功能,体现数据库的增删查改,比如
一个错误结果的改正、不存在的条目的增加[ ] 拍照功能按钮 —>查询数据库返回结果—>弹窗显示,能否给出几个结果,并且是按照置信度递增或递减排列显示
[x] 轮播图(点缀)
[x] 用户中心的历史记录查询入口—-历史记录,分包加载;使用POST接口传递用户id到后端查询即可
[x] 使用手册入口-使用手册,分包加载
用户信息页
元素设计:
- [x] 头像名称—绑定全局共享变量
- [x] 按钮展示,grid-list设计
分类百科
元素设计:
- [ ] 列表呈现一些生活小常识
问题
- 全局变量存储机制,不能简单的通过设置
const app=getApp()来修改全局变量值,采取更好的方式- 接口调用时,对于集合的结果,尽量使用循环语句,将结果按规律呈现
- 分包的预加载选项,后期可以尝试,在进入指定的某一页面后选择加载指定的分包数据,这样当浏览该分包页面时就能够比较流畅的进入了
API的promise化能够很好的解决回调地狱的问题,是比较好的API请求迭代方式
2️⃣交互功能的逻辑编写
1️⃣进入小程序首页,弹窗登录提示,选择登录/游客(后台存储用户信息到临时缓存中)
- [x] 点击登录进入登录页面,登录注册完成后重新进入首页,此时系统可使用的功能是用户模式下的
- [x] 点击游客则关闭弹窗,此时系统的功能仅为游客模式下的
具体实现步骤:
- 在
app.js中调用内置函数setStorage在小程序刚启动时注册全局信息到缓存中 - 进入首页后,同样在
home/index.js下加载方法,并读取全局信息根据登录状态,设置提示登录弹窗,包含游客和登录两个选择- [x] 选择游客后,将会调用函数
setStorage将use_status设置为游客模式,后台的API会进行对应模式下的处理 - [x] 选择用户后,进入登录/注册页面,通过输入表单信息进行注册或登录,完成后将重新跳转到主页,并弹出类似
欢迎用户XX的提示框以告知你的登录状态,表单输入过程中注意双向绑定数据,及时更新 - [x] 如果游客模式下想要登录,可在用户中心页面进行登录(点击头像或用户名),登录界面相关的操作和上面步骤相同
- [x] 选择游客后,将会调用函数
2️⃣ 渲染指南页面
- 调用API获取一级垃圾分类数据,设置左侧一级滚动侧边栏的激活方式
- [x] API调用设置参数的问题,要检索出所有一级分类
- [x] 设计列表样式,一级与二级不同,且具备激活状态
- 获取对应一级分类下的二级分类数据,通过一级分类的id作为参数调用API在数据库检索
- 可以添加垃圾分类知识相关的内容
完成情况:已完成
3️⃣ 在搜索框输入可以文字搜索垃圾所属分类,跳转到新页面获取,搜索框可以重置
- [x] 封装API,设计首页输入框的样式
- [x] 触发搜索后跳转到结果显示页面,携带从服务端返回的结果数据,渲染到结果页,附加对应的垃圾分类知识
- [ ] 文字搜索若无结果,则可以提交更新分类信息到后台,再由后台管理后续审核
完成情况:已完成
4️⃣ 实现拍照识别功能
- [x] 测试模型的推测功能能否在本地使用
[ ] 功能封装成API,调用API可能返回结果的等待时间会长一些,可以设置一个
加载动画来过渡[ ] 结果不是唯一,而是按照置信度多个成列表递减显示
- [x] 已登录状态下仍会保存查询记录信息
- [ ] 对拍照识别结果提出纠正,并同步到数据库中,在数据库后台显示的时候根据
file_path字段来判断,若为默认值即未写入图像,则渲染为空的div;否则显示图片
文字查询通过查询内容体现,更新查询内容,无需设置文件路径
图像识别通过上传图像体现,将用户确认后的查询内容提交,更新查询内容和文件路径,以及审核状态
查询结果用正确的;纠正的,纠正的由后台进行审核;图像上传到后台,将保存,用于后续模型训练
从多个里面选择一个加以确认或者找不到的结果提出纠正,并交由后台进行处理
小程序端调用并同样跳转到新页面显示结果
完成情况: 拍照识别预测功能可正常运行,有待完善
- 用户权限:所有可用功能,包括增加分类数据,修改密码等
- 游客的权限:不保存搜索记录的情况下
- 拍照搜索
- 文字搜索
服务端(Django)
1️⃣数据库设计
根据系统的功能需求分析,本系统需要使用的数据信息表有三个
TC_USER、TC_CATE、TC_SEARCH,分别表示用户信息,垃圾分类信息以及用户搜索历史各模型的数据格式如下图示:
User模型的自定义
由于Django自带了User模型,但为了方便并且符合我自己的设定,需要对默认的User模型进行覆写,重新定义一个自己的User模型并将其设置为系统使用的默认User模型。步骤如下:
问题
- 使用不同的方式添加用户信息条目到数据库时,密码并不全是加密显示
1 | |
引申点:如果当我要修改用户密码时,怎样能够保证修改的密码依然是加密形式的;更新数据库的信息也有默认的update()方法但会出现和save()一样的情况吗
- 使用mysql
1 | |
先将用户登录以及注册相关API实现,不着急其他功能,接下来转向小程序端进行设计,为了测试是否能够顺利地通过小程序与Django进行数据通讯
微信小程序有它自己的微信用户验证登录方式,暂时不采用,将来可以更换这种登录方式
利用Postman进行一个简单的接口调用测试(实现登录验证的功能)
- 登录状态的保持,对于小程序数据生命周期的理解
- globalData:存储短期数据,引入 app.js 可访问,彻底关闭小程序数据消失 (也就设置全局变量,但需要通过app.js引用)
- Storage:存储长期数据,全局可访问,移除小程序数据消失
- 后端服务器:存储跨设备的数据,通过后端授权后可访问,只要服务器不炸数据永存
- 从用户中心跳转查看历史数据时,设置navigate跳转的
url字段需要携带参数?userid=xxx,这样就可以通过后台查询对应用户的历史记录
其他数据表的建立代码展示….
2️⃣API编写
一、用户信息相关的功能
- [x] 用户登录—核对账号与密码
- [x] 用户注册的功能—核对账户与密码,没有则创建
二、拍照识功能
三、搜索垃圾分类
- 引用素材问题,借助图床外部引入图片,并且借助循环语句,只要上传时按顺序编号即可方便引用
- 文字搜索功能
3️⃣与客户端进行通讯
4️⃣使用深度学习模型
开发补充
- 开发过程用到git代码管理
1 | |
- Django.httprequest.POST的对象类型是一个QuerySet(类似字典对象,属于继承),需要理解他的一些内置属性
request.post.get('name')可以获取请求报文中携带的表单中的指定变量的数据
待解决问题:
在Django环境下单独运行Python脚本
Django项目需要生成requirements.txt 上传到github
开题报告
研究背景与意义
- 垃圾分类的概念与作用
- 垃圾分类在我国的发展,垃圾分类在国外的进行状况对比
- 垃圾分类目前发展的瓶颈即遇到的困难,比如公民垃圾分类意识淡薄
垃圾分类有利于保护环境,可是,严苛的分类标准和条例却让国人叫苦不迭,由于人为处理较为复杂、意识和习惯未形成,“垃圾分类难”深深困扰着大众。垃圾智能回收箱、垃圾分类机器人可助力垃圾分类。
- 引出智能化的重要性,以及小程序作为用户端的可行性,然后是我的项目是如何做的,带来怎么样的好处
参考百度词条补充内容 垃圾分类](https://baike.baidu.com/item/垃圾分类/2904193))
主要内容
系统的工作机制和用户操作流程?
拟研究方法
- 测试时,10-cross testing方式随机测试
- 训练时采取多种修改分辨率(图像尺寸)
- 图像增强可以举例子展示
实验对比:垃圾分类40类
| ResNet(layer) | 训练批次 | batch_size | 优化器 | 学习率 | 验证集精确度 |
|---|---|---|---|---|---|
| ResNet50 | 50 | 128 | Adam | 0.001 | |
| 50 | 50 | 128 | SGD | decay | |
| 50 | 50 | 128 | SGDM | 分段设置学习率 | |
| 101 | 50 | 128 | Adam | 0.001 | 0.51 |
| 101 | 50 | 128 | SGD | 分段学习率 | 0.68 |
| 34 | 50 | 128 | SGDM | 分段学习率 | |
| 50 | 50 | 128 | SGDM | 分段学习率 | 0.68 |
| 50 | 50 | 32 | SGDM | 分段学习率 | |
| 101 | 50 | 128 | SGDM | 分段学习率 | 0.70 |
| 152 | 50 | 128 | SGDM | 分段学习率 | 0.71 |
数据分布
- 将数据集分布情况可视化,先存到json文件中,然后放到本地用echarts来制作,更方便且更优化
- 对数据量较少的数据集进行适当补充
垃圾分类知识
- 可回收物:废纸,塑料,金属,玻璃制品和布料
- 湿垃圾:剩菜剩饭、瓜皮果核、花芬绿植、过期食品(膨化食品,零食,变质面包)、茶叶
- 有害垃圾:
- 干垃圾:餐盒、餐巾纸、湿纸巾、卫生间用纸、塑料袋、食品包装袋、污染严重的纸、烟蒂、纸尿裤、一次性杯子、大骨头、贝壳、花盆、陶瓷等
对来自多方的数据集进行合并重新筛查,删掉一些大小过小的无法提取特征的图片,可以再爬取一些图片
数据集问题
- 牙膏与牙膏盒子是不同类的,盒子一般纸质,可回收;牙膏皮牙膏都是其他垃圾
- 数据集太小
- 训练过程中使用数据增广
- 数据集存在部分图片几乎相同,重叠的问题
- 使用k折交叉验证设置验证集来优化训练效果,k设置5或者10,但这样就意味着训练过程费时间费算力
- 该方法的目的是什么?是保证所有数据都能够参与训练,最后我们只需要关注参数改变为模型效果带来的影响(以后做)
总结
- 学习的是使用框架以及图像分类的操作思路,但不是虽然可以用封装好的方法去模拟训练过程,但还是有很多细节不懂
模型学的究竟是什么东西,权重的含义是什么,是如何表达出目标语义信息的?
- 卷积神经网络学到的东西有哪些—图像的信息有哪些?
- 特征是如何表达的,不同的通道存储了哪些信息,又是如何存储的
ReLU、激活函数的概念,作用,带来的优势又是如何体现的
最大池化的好处在于,该方法放大了一个被找到的图像特征与其他特征的相对位置的关系的重要性,要比该特征在同一张图像中的具体位置更为重要。
如何理解?—特征之间的相对位置,层次感
毕业论文
有待补充,调参过程以及实验对比结果展示
对网络结构还需要深入了解
答辩问题:
- 为什么要用ResNet?
寻找可量化比较的数据来对比ResNet与其他网络,得出使用ResNet是相对好的
- ResNet的特点
- 残差块
- 捷径连接,防止了过拟合
- 使用了含瓶颈结构的残差块来堆叠,瓶颈结构可以在训练过程中降低纬度,然后再还原;
- 可以在训练过程中减少参数量,进而减少了运算占用内存
- 图像处理时,没有使用等比例缩放与使用等比例缩放的效果对比
- 为什么要卷积核的相加,然后才说统一尺寸;卷积核的个数又是如何确定的?
- 每一个卷积层的操作是怎么计算的?
- BN与ReLU的顺序能否更换?
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!